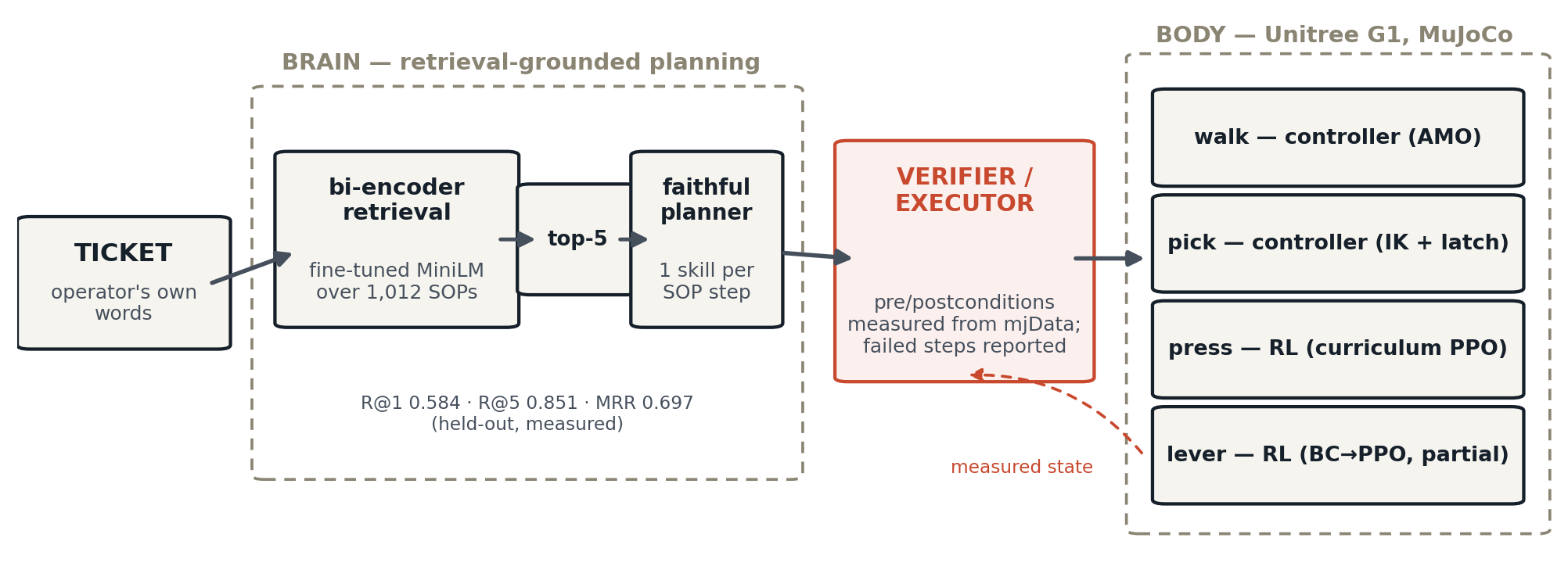
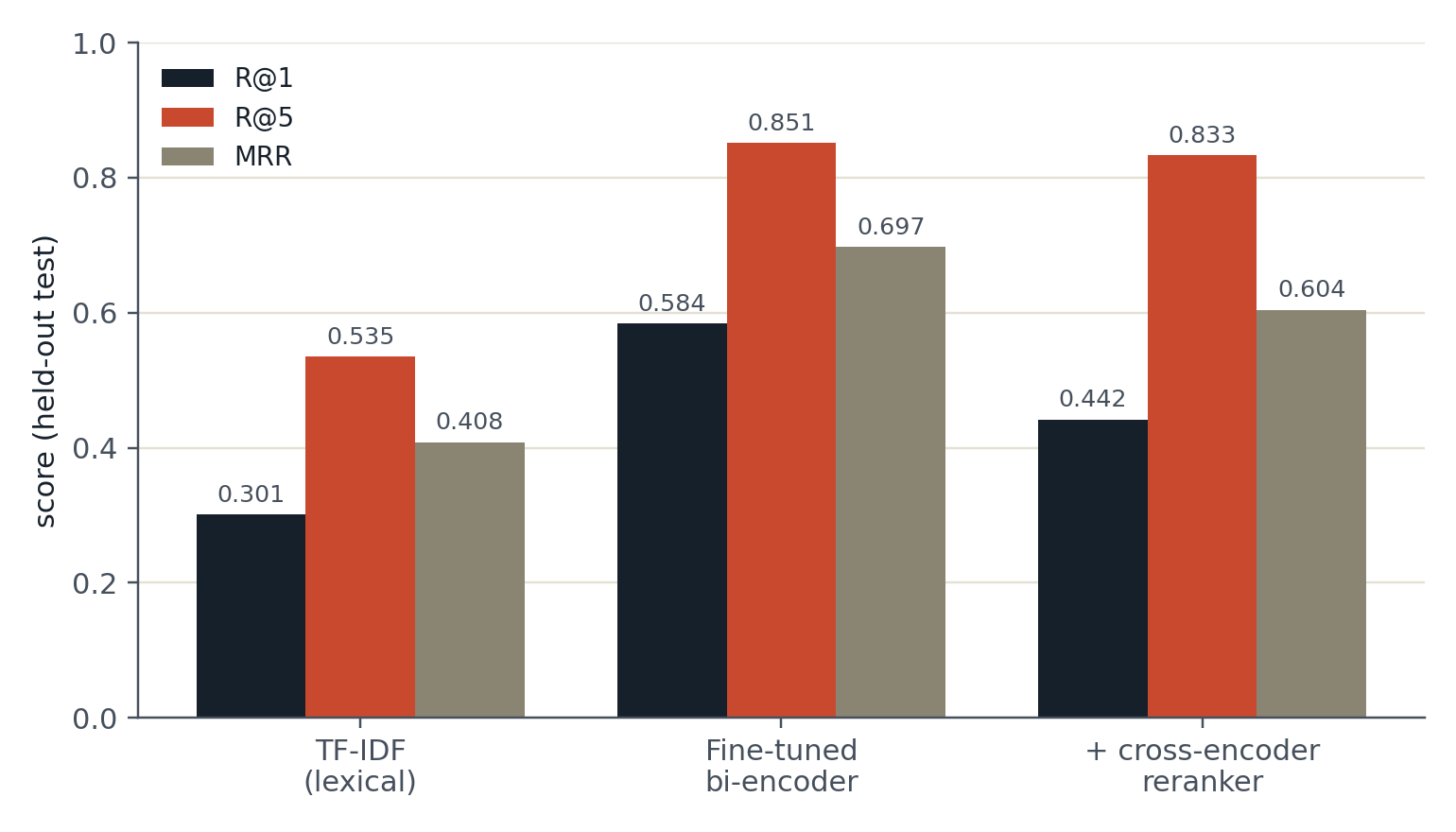
01 · Overview
System overview.
The system has two parts joined by a typed contract: a brain that turns language into a sequence of skills, and a body, a Unitree G1 with an added gripper in MuJoCo, that executes it. A verifier checks every precondition and postcondition from simulator state rather than from the policy’s own report. It measures the outcome whether a controller or a learned policy produced the motion.